

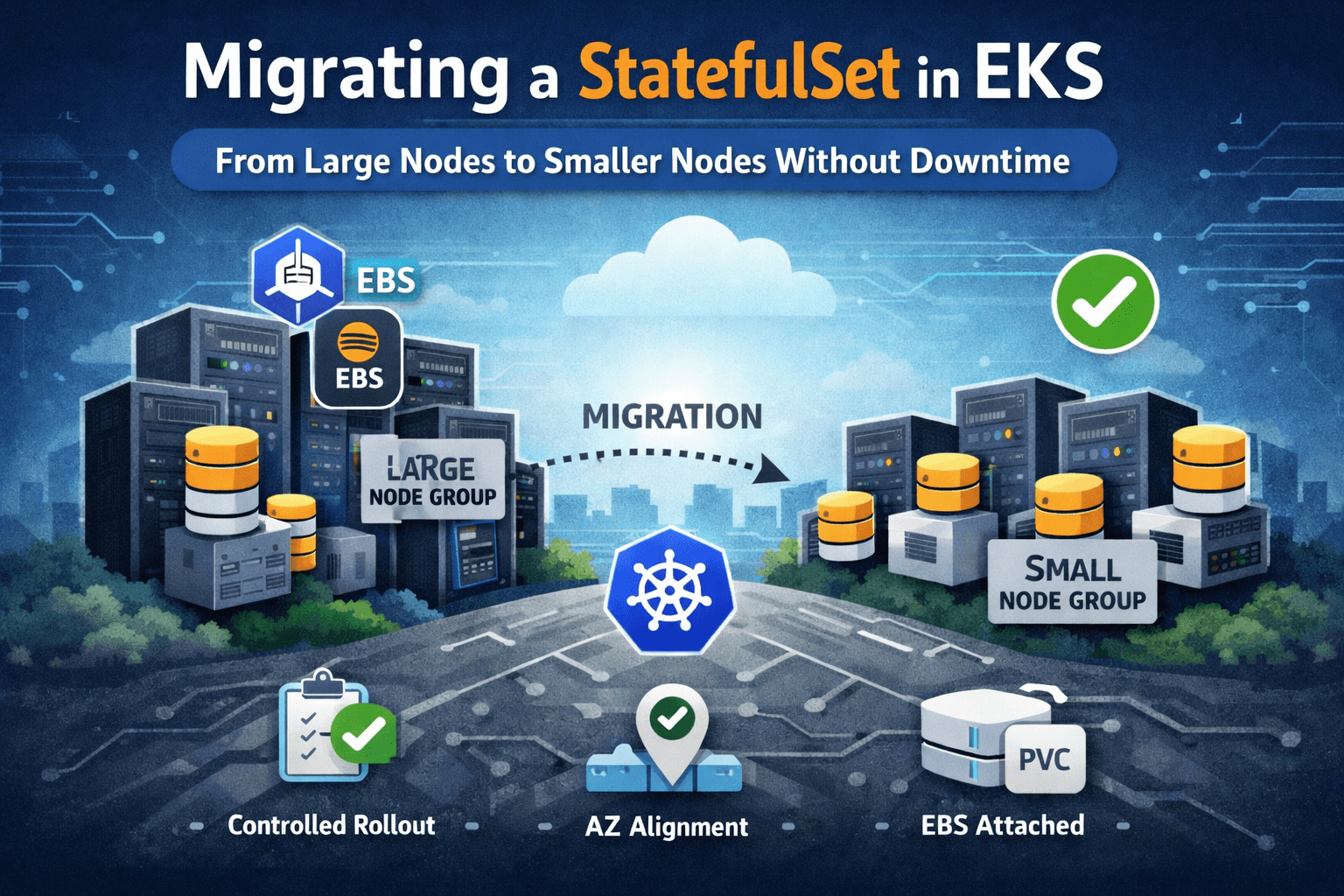
Production Change: Migrating a StatefulSet from Large to Smaller Nodes in EKS (Without Downtime)
A real production change where we safely migrated a StatefulSet from large to smaller EKS node groups without downtime.
Search for a command to run...
A real production change where we safely migrated a StatefulSet from large to smaller EKS node groups without downtime.
No comments yet. Be the first to comment.
This migration was performed on a production workload where cost reduction was prioritized over zone-level high availability.
1. Overview What I Designed I designed a hybrid infrastructure architecture: Terraform → Foundation Layer Crossplane → Dynamic Lifecycle Layer ArgoCD → GitOps Enforcement This created a continuou

Cross-cloud VM migration is not a disk copy task. It is: An access model transformation A replication lifecycle management exercise A downtime control operation A cost boundary decision We execu
When AWS introduced AWS DevOps Agent, I was less interested in feature lists and more interested in one practical question. Can it actually reduce investigation time during real production-style failu

Migrating object storage across cloud providers is not a copy task.It is a cost, network, and security boundary problem. We migrated 10+ TB of object data from Google Cloud Storage to Amazon S3 under

We had a production application running on Amazon EKS as a StatefulSet.
Each replica had its own PersistentVolumeClaim backed by Amazon EBS.
During the initial launch phase, we deployed the workload on large instances to remove any performance uncertainty.
After a few weeks of monitoring, the data was clear:
CPU utilization consistently below 35%
Memory below 40%
No disk pressure
Stable traffic and latency
We were clearly over-provisioned.
The goal was straightforward:
Move the StatefulSet from a large node group to a smaller node group to reduce infrastructure cost — without downtime.
This was a live production system.
We had two managed node groups:
aws-devops-agent-eks-test-ng1 (large instances)
migration-ng (smaller instances)
Workload characteristics:
StatefulSet with 3 replicas
Each pod had its own PVC (created via volumeClaimTemplates)
StorageClass backed by EBS
PodDisruptionBudget configured:
maxUnavailable: 1
Before touching the production workload, we tested the entire flow using a demo Nginx StatefulSet with PVCs. This allowed us to observe storage detach/attach behavior safely.
Changing the nodeSelector modifies the pod template inside the StatefulSet:
spec:
template:
spec:
nodeSelector:
Any change under spec.template updates the pod template hash.
That automatically triggers a rolling update.
No manual restart command is required.
For each pod, Kubernetes performs the following lifecycle:
Terminate pod on the old node
Detach the EBS volume
Schedule pod on a new node
Attach the same volume
Mount filesystem
Start container
Wait for readiness probe
Because this is a StatefulSet:
Pod identity remains stable
PVC remains the same
The EBS volume remains in its original Availability Zone
The primary risk during migration is not parallel restarts — StatefulSet prevents that by default.
The real concern is restart pacing and storage stability between transitions.
We defined:
podManagementPolicy: OrderedReady
StatefulSet supports two policies:
OrderedReady
Parallel
With OrderedReady:
Pods are terminated in reverse ordinal order (pod-2 → pod-1 → pod-0)
The controller waits for a pod to become Ready before proceeding to the next one
This guarantees serialized lifecycle transitions.
Only one pod is ever moving at a time.
For storage-backed workloads, predictability is more important than speed.
Originally:
minReadySeconds: 30
During migration, we increased it:
minReadySeconds: 60
This does not delay traffic.
It delays rollout progression.
The behavior becomes:
Pod becomes Ready
Controller waits 60 seconds
Then proceeds to the next pod
That buffer provides:
Storage stabilization time
Application warm-up window
A monitoring observation period before the next restart
OrderedReady ensures serialization.
minReadySeconds ensures pacing.
Together, they create controlled transitions.
The PodDisruptionBudget does not control rolling update speed.
It protects against voluntary disruptions such as:
Node drain
Evictions
Autoscaler actions
With:
maxUnavailable: 1
We ensured that even outside the rollout logic, no more than one pod could be voluntarily disrupted at a time.
This preserved availability guarantees during infrastructure operations.
EBS volumes are Availability Zone bound.
Because PVCs were already provisioned, each PersistentVolume existed in a specific AZ.
Before migration, we verified:
The smaller node group spans the same AZs as the large node group
There is node capacity in those AZs
If a pod’s volume resides in ap-south-1a, the new node must also be in ap-south-1a.
Otherwise, the pod remains Pending due to volume node affinity constraints.
This check is mandatory for StatefulSet migrations using EBS.
Only two fields were modified.
Before:
minReadySeconds: 30
nodeSelector:
eks.amazonaws.com/nodegroup: aws-devops-agent-eks-test-ng1
After:
minReadySeconds: 60
nodeSelector:
eks.amazonaws.com/nodegroup: migration-ng
Everything else remained unchanged.
Small change. Controlled blast radius.
Steps:
Created the smaller node group (migration-ng)
Verified AZ alignment and resource headroom
Updated the StatefulSet manifest
Applied the updated configuration:
kubectl apply -f statefulset.yaml
Because the pod template changed, the StatefulSet controller automatically initiated a rolling update.
We first executed this full flow using the demo Nginx StatefulSet to validate behavior before applying it to the production workload.
For each replica:
Pod terminated on the large node
EBS detached
Pod scheduled onto a smaller node in the same AZ
Volume attached
Pod became Ready
Controller waited 60 seconds
Next pod restarted
There were no overlapping transitions.
No downtime.
No error spike.
Stable latency throughout.
Before:
3 large instances
After:
3 smaller instances
Outcome:
Reduced compute cost
Preserved availability
Maintained performance
No operational instability
This was not just resizing infrastructure.
It was a controlled lifecycle transition of a stateful workload.
StatefulSet migrations are safe when you:
Respect controller behavior
Serialize restarts
Add rollout pacing
Validate storage topology
Test with a safe workload first
That’s exactly what we did.
And the migration completed without downtime.