

Production Incident: Control Plane Latency During Large-Scale Rollout on Amazon EKS

Search for a command to run...
No comments yet. Be the first to comment.
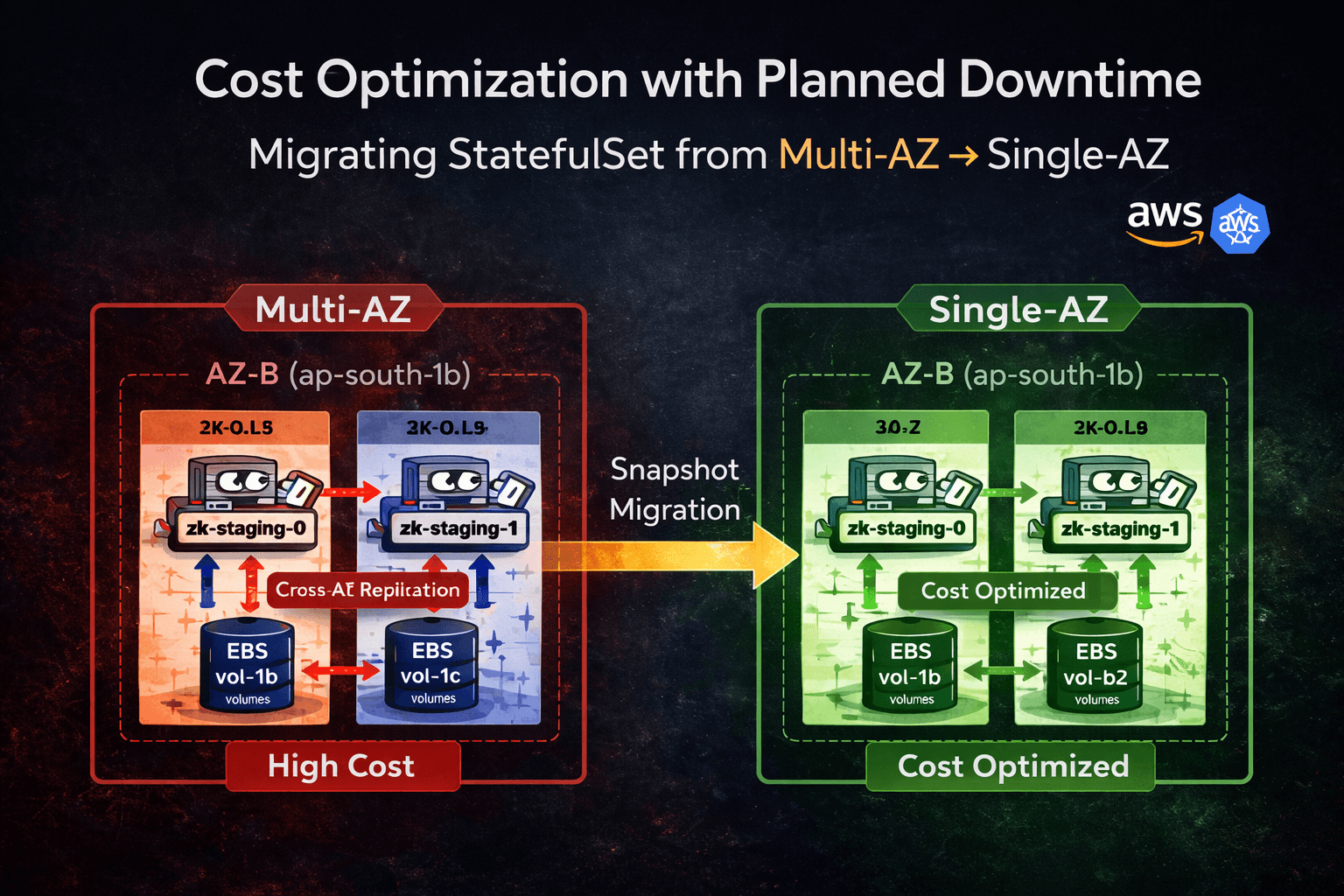
This migration was performed on a production workload where cost reduction was prioritized over zone-level high availability.
1. Overview What I Designed I designed a hybrid infrastructure architecture: Terraform → Foundation Layer Crossplane → Dynamic Lifecycle Layer ArgoCD → GitOps Enforcement This created a continuou

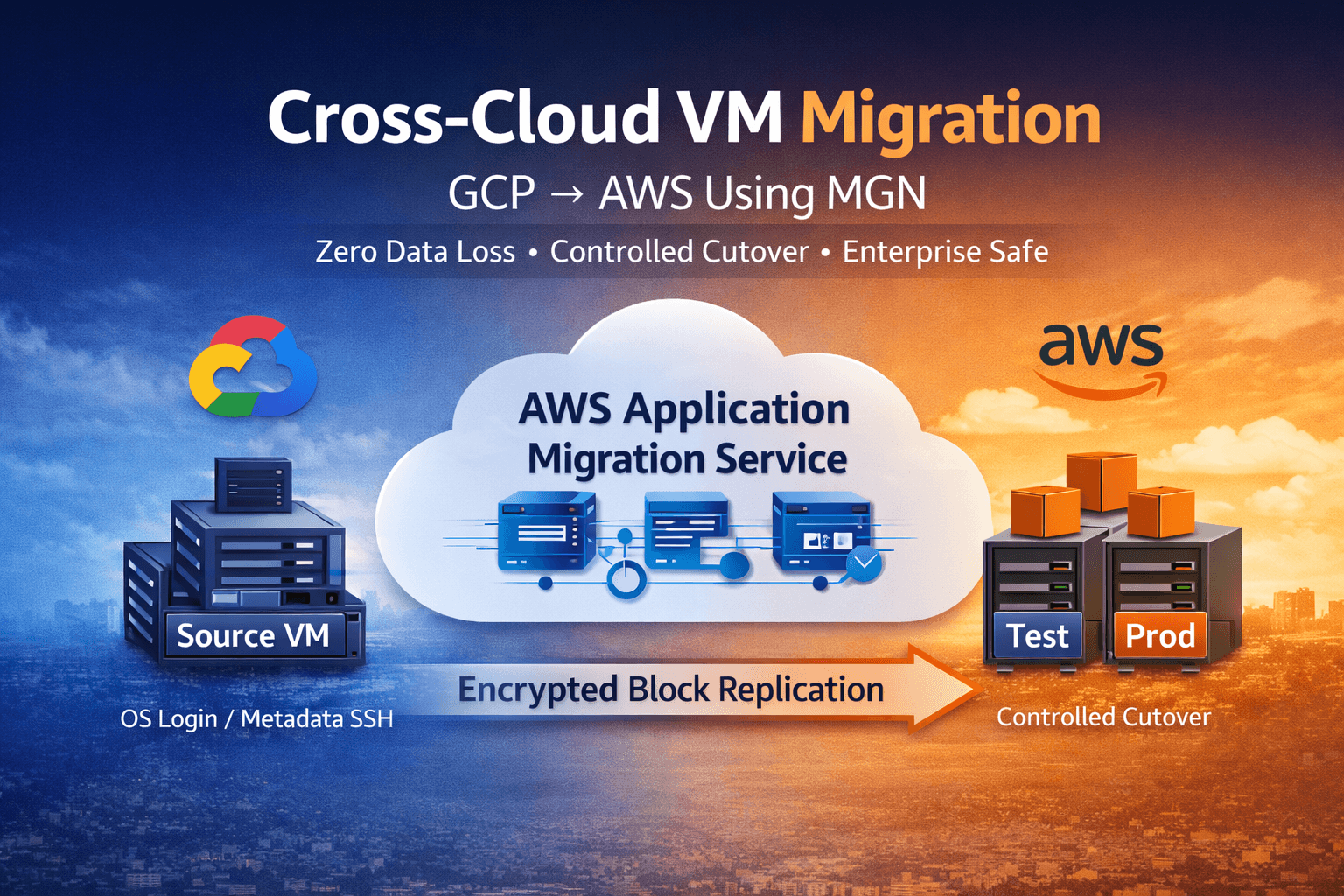
Cross-cloud VM migration is not a disk copy task. It is: An access model transformation A replication lifecycle management exercise A downtime control operation A cost boundary decision We execu
When AWS introduced AWS DevOps Agent, I was less interested in feature lists and more interested in one practical question. Can it actually reduce investigation time during real production-style failu

Migrating object storage across cloud providers is not a copy task.It is a cost, network, and security boundary problem. We migrated 10+ TB of object data from Google Cloud Storage to Amazon S3 under

As part of readiness planning for high-demand production scenarios, we executed a large-scale rollout simulation on one of our production clusters running on
Amazon Elastic Kubernetes Service.
The cluster hosts thousands of pods, supports active CI/CD workflows, and runs with autoscaling enabled.
To validate system behavior under operational stress, we triggered an update of approximately 2000 pods in parallel.
The objective was simple: identify performance boundaries before peak traffic windows.
During the rollout:
kubectl get pods responses became noticeably slow
Deployment progression slowed
CI pipelines interacting with the cluster experienced delays
API response times increased
There were:
No worker node failures
No pod crashes
No autoscaling instability
Once the rollout completed, API performance returned to normal.
CloudWatch Container Insights showed:
A sharp spike in API server request volume
Increased API server latency
Minor request drops during peak rollout
Automatic normalization after rollout completion
The behavior was consistent during heavy parallel updates.
This indicated temporary control plane saturation under burst traffic.
Updating ~2000 pods simultaneously generated significant API traffic, including:
Pod create and update requests
Deployment controller reconciliation
Watch stream updates
kubelet status reporting
Autoscaler interactions
CI/CD polling
All of these operations flow through the Kubernetes API server.
By default,
Amazon Elastic Kubernetes Service
uses reactive auto-scaling for its control plane.
Reactive scaling introduces a short window where burst request volume can temporarily exceed allocated API capacity before scaling adjusts.
During that window:
API latency increases
kubectl commands respond slowly
Rollout completion time extends
The system stabilizes once traffic decreases and scaling catches up.
This was a burst capacity boundary — not a failure.
Under normal operating conditions, temporary latency during heavy rollout may be acceptable.
However, during high-demand production windows:
Deployment speed directly impacts mitigation time
Autoscaling responsiveness is critical
API stability affects operational recovery
Control plane latency becomes an operational risk during peak events.
To eliminate the burst latency window, we evaluated Provisioned Control Plane in
Amazon Elastic Kubernetes Service.
Provisioned Control Plane allows selecting predefined control plane capacity tiers instead of relying entirely on reactive scaling.
This provides:
Reserved API throughput
Predictable control plane performance
Reduced throttling during heavy rollouts
Improved stability under burst conditions
Higher tiers provide greater sustained API capacity, with increased operational cost.
We decided to validate the higher control plane tier in non-production first.
Steps performed:
Upgraded the control plane tier.
Re-ran heavy rollout simulations.
Compared API latency and request drop metrics.
Evaluated stability improvement versus cost impact.
Command used:
aws eks update-cluster-config \
--name apps-eks \
--control-plane-scaling-config tier=tier-xl
Verification:
aws eks describe-cluster --name apps-eks
Production rollout will be based on measured improvement and cost justification.
Large clusters expose control plane limits during parallel rollouts.
Reactive scaling introduces short latency windows under burst traffic.
Deployment scale directly influences API server performance.
Control plane capacity planning must be part of production architecture decisions.
Provisioned Control Plane is suitable for environments with frequent heavy updates or high operational demand.
The incident did not cause downtime or workload failure.
It identified a control plane burst capacity boundary during large-scale rollout testing.
By addressing it during readiness validation, we reduced operational risk before peak demand scenarios.