Cross-Region RDS Disaster Recovery: Production Failover Architecture
1. Overview
This post documents how I designed and implemented cross-region disaster recovery for a production MySQL database running on Amazon RDS.
The requirement was straightforward:
If the primary region (ap-south-1) becomes unavailable, the database must recover automatically from another region with minimal downtime and no manual intervention.
The approach relies entirely on native AWS services and focuses on controlled automation rather than introducing additional orchestration layers.
2. Problem Statement
The application was running with:
A single primary RDS instance in ap-south-1
No cross-region replica
A manual disaster recovery procedure
In the event of a regional failure:
The database endpoint would become unreachable
The application would lose connectivity
Recovery would depend on human response time
This created an unacceptable recovery model for a production-facing workload.
The goal was to introduce regional resilience while keeping the system operationally predictable and architecturally simple.
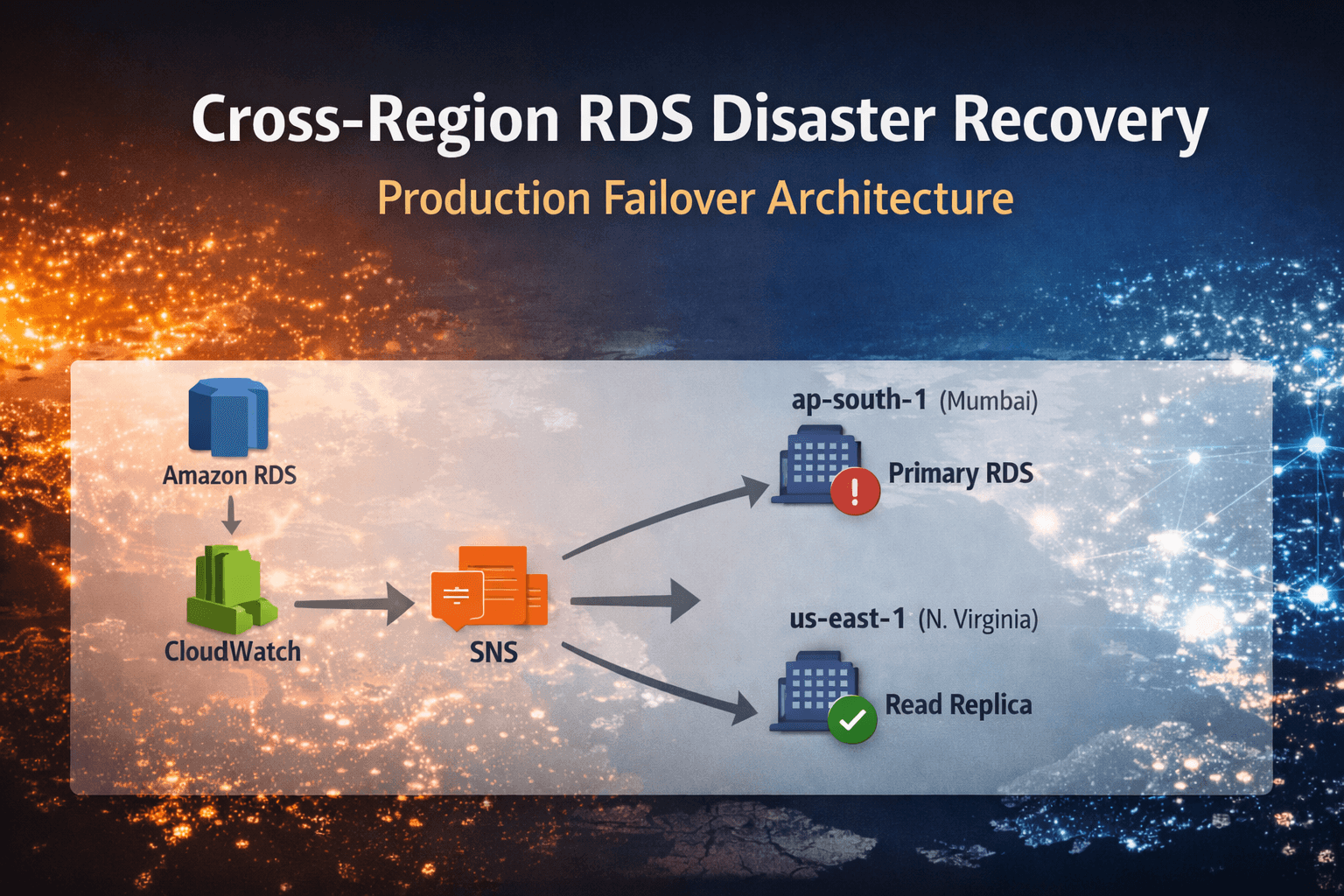
3. Architecture After DR Implementation
Application
↓
Primary RDS (ap-south-1)
↓
Cross-Region Read Replica (us-east-1)
Automation Flow:
CloudWatch Alarm
→ SNS Topic
→ Lambda (us-east-1)
→ Promote Read Replica
After promotion, the replica becomes a standalone primary database.
4. Design Decisions
4.1 Cross-Region Read Replica
A read replica was created in us-east-1 from the primary RDS instance.
Replication is managed natively by RDS.
Important consideration:
Cross-region replication is asynchronous. This introduces a non-zero Recovery Point Objective (RPO). A small amount of recent data may not be replicated during failover.
For this workload, that trade-off was acceptable.
4.2 Failure Detection
Failure detection was implemented using Amazon CloudWatch.
A CloudWatch alarm was configured on the primary instance. The initial metric used was:
DatabaseConnections < 1
If the instance stops accepting connections, the alarm transitions to ALARM state.
In more mature setups, detection can be improved using:
RDS instance status
RDS event notifications
Composite alarms
The alarm publishes its state change to an SNS topic.
4.3 Event Routing
Amazon Simple Notification Service was introduced to decouple monitoring from execution.
The flow:
CloudWatch → SNS → Lambda
This separation provides:
Clear event-driven architecture
Loose coupling
Extensibility for future automation
4.4 Automated Promotion
Promotion logic was implemented using AWS Lambda in us-east-1.
The Lambda role was granted minimal permission:
rds:PromoteReadReplica
Core logic:
import boto3
def lambda_handler(event, context):
client = boto3.client('rds', region_name='us-east-1')
replica_id = "your-read-replica-id"
client.promote_read_replica(
DBInstanceIdentifier=replica_id
)
return {
"statusCode": 200,
"message": f"Promotion initiated for {replica_id}"
}
When triggered, Lambda initiates promotion of the replica. Promotion typically completes within a few minutes.
5. DNS Consideration
Promotion alone does not restore application traffic.
The application must connect to the new primary endpoint.
This is typically handled using Amazon Route 53 with:
Failover routing policies
Health checks
Low TTL configuration
Without DNS integration, traffic would continue to target the failed endpoint.
This is a critical part of the disaster recovery strategy.
6. Validation Process
To validate the setup:
The primary instance was stopped
CloudWatch alarm triggered
SNS published the event
Lambda executed
The read replica was promoted
Post-promotion validation included:
Verifying instance state
Testing database connectivity
Executing queries
Confirming application behavior
Failover occurred without manual intervention.
7. Cost and Trade-offs
Cross-region disaster recovery increases infrastructure cost:
An additional RDS instance
Cross-region replication traffic
Additional storage
This cost is deliberate and justified by the reduction in downtime risk.
RTO: A few minutes (detection + promotion time)
RPO: A few seconds (due to asynchronous replication)
These expectations must be clearly defined with stakeholders before implementation.
8. When This Approach Makes Sense
This architecture is suitable when:
A few seconds of data loss is acceptable
Automated regional failover is required
Operational simplicity is preferred
The workload is not using Aurora Global Database
For workloads requiring near-zero RPO and faster failover, managed global database architectures may be more appropriate.
9. Final Takeaway
I implemented a cross-region disaster recovery architecture for Amazon RDS using native AWS services.
The system:
Detects primary failure automatically
Triggers event-driven automation
Promotes a cross-region replica
Reduces human dependency during outages
The design balances simplicity, cost, and resilience. It introduces regional fault tolerance without adding unnecessary operational complexity.